
Aquin SDK — Use Cases Documentation
QLoRA Fine-Tuning of LLaMA 3.2-1B Instruct on a Healthcare Domain Dataset
Sambhav Choudhary · Aquin Labs · May 2026
Aquinf03/llama3.2-1b-qlora-healthcare-case-study↗1. Abstract
This document details a real-world use case of the Aquin SDK for monitoring and diagnosing QLoRA fine-tuning of a large language model. The project fine-tunes Meta's LLaMA 3.2-1B Instruct model on a specialised JSONL dataset covering Exdensur (depemokimab) — a GSK-manufactured IL-5 antagonist approved in the EU and US — alongside broader healthcare topics including gene editing, regenerative medicine, AI-assisted diagnostics, and brain-computer interfaces. The objective is a capable domain assistant that answers factually about modern healthcare innovation.
Training was executed locally on a GCP VM using Python with the Hugging Face Transformers and PEFT libraries. The Aquin SDK was integrated directly into the training loop via a single attach_qlora() call, providing real-time streaming of loss, learning rate, gradient norms, and deeper diagnostic signals (dead layers, dead attention heads, LR decay warnings) to the Aquin dashboard — without any modification to the core training logic.
2. Project Setup
2.1 Environment
The training environment ran on a Google Cloud Platform VM (Debian Linux, Python 3.13.0 via pyenv). GPU-backed NF4 quantisation was handled by BitsAndBytes, and the LoRA adapter was applied via the PEFT library. The Aquin SDK was installed as a pip package and required only an API key.
2.2 File Structure
src/
├── main.py # Entry point — config, trainer, Aquin session
├── train_qlora_aquin.py # QLoRAConfig, TextDataset, QLoRATrainer
├── data_loader.py # JSONL loader — formats prompts for Instruct template
├── sdk_impl.py # Utility wrapper around attach_qlora()
└── dataset-2.jsonl # ~500 row domain Q&A dataset2.3 Aquin SDK Integration
The SDK was integrated with three lines of code. After initialising the trainer, a session was attached by passing the model and optimiser references alongside the API key. Each training step calls session.step(loss) to stream metrics, and session.stop() finalises the run.
from aquin import attach_qlora
session = attach_qlora(
model=trainer.model,
optimizer=trainer.optimizer,
api_key=API_KEY
)
trainer.train(dataset=dataset, session=session)
session.stop()This minimal integration is the core SDK use case: the training code requires no awareness of Aquin internals. The dashboard updates live, and the Metrics Chat on the left panel provided actionable diagnostics throughout every training iteration.
3. Dataset
The dataset (dataset-2.jsonl) contains approximately 500 prompt-completion pairs structured as short Q&A. Each row is a JSON object with a "prompt" and a "completion" key. Topics span:
- Exdensur (depemokimab) — mechanism, dosing, approvals, clinical trial data
- Gene editing — CRISPR, off-target risks, gene therapy vs drug therapy
- Regenerative medicine — stem cells, tissue engineering, organ preservation
- AI in healthcare — diagnostics, radiology, drug discovery, hospital automation
- Brain-computer interfaces — paralysis restoration, neural decoding
- Wearables & smart fabrics — continuous monitoring, biosensors
- Predictive and personalised medicine — genomics, microbiome, digital twins
The data_loader.py file formats each row into the LLaMA 3.2 Instruct chat template before tokenisation, and returns a response_start_marker so the TextDataset can mask prompt tokens from the loss — training the model only on completion tokens.
text = (
f"<|start_header_id|>user<|end_header_id|>\n\n"
f"{prompt}<|eot_id|>"
f"<|start_header_id|>assistant<|end_header_id|>\n\n"
f"{completion}<|eot_id|>"
)
marker = "<|start_header_id|>assistant<|end_header_id|>\n\n"4. Training Iterations & Aquin Diagnostics
Four training runs were conducted in sequence. Each run was informed by the diagnostic signals surfaced by Aquin in the previous one. The table and analysis for each run document the configuration, what Aquin flagged, why it happened, and what was changed in response.
Run 1 — Baseline
LLaMA 3.2-1B Base · Conservative LoRA config
The first run established a baseline using the pre-RLHF base model with a minimal LoRA configuration: rank 16, only query and value projections as target modules, and a linear LR schedule with a 3% warmup ratio. The objective was to measure raw domain adaptation before introducing any complexity.
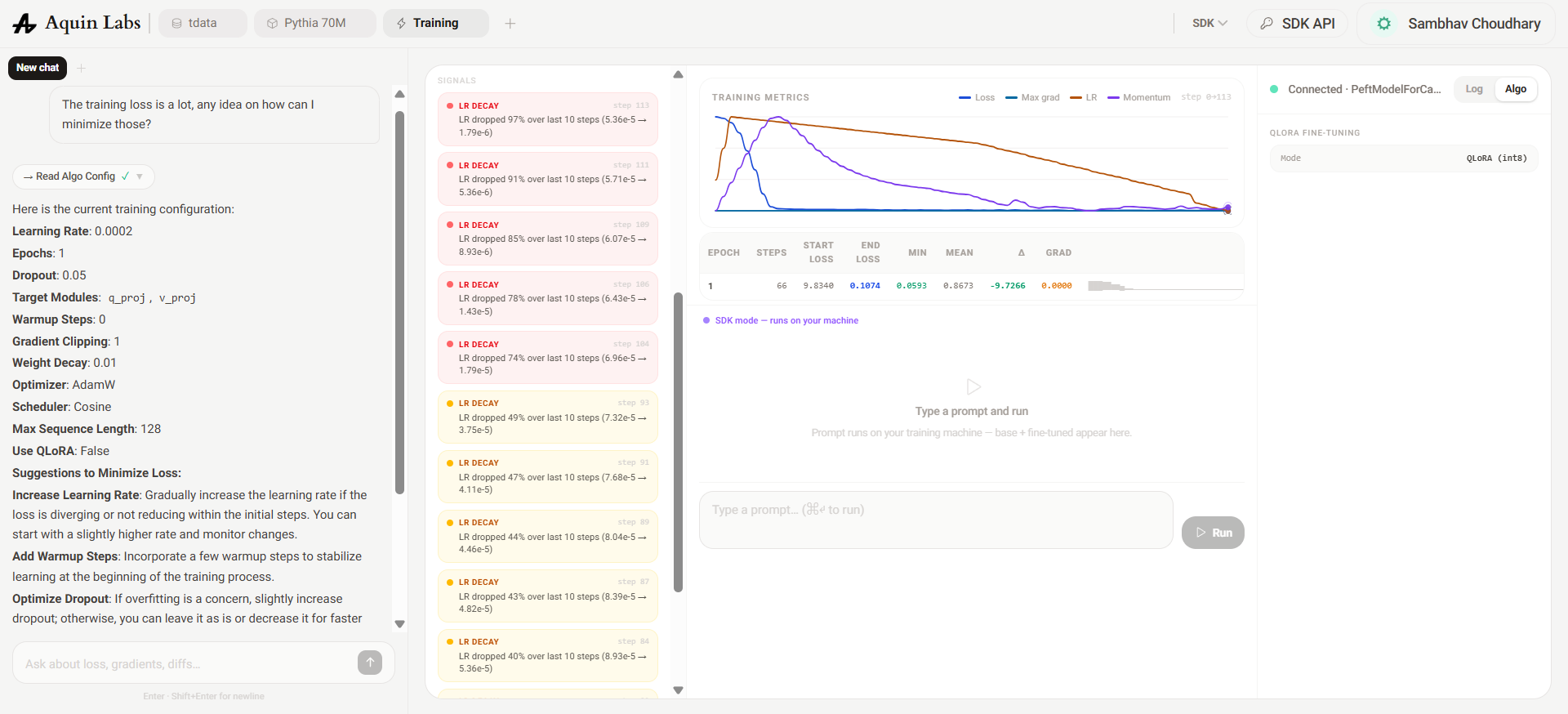
Aquin's Metrics Chat flagged a persistent LR DECAY signal: the learning rate was collapsing by ~67% across every 10-step window from step one. With only a 3% warmup ratio, the linear scheduler peaked and began decaying almost immediately — the model had barely started learning before the LR fell into a range too low to drive meaningful weight updates. End loss of 1.68 after one epoch on a narrow domain dataset suggested the model was making surface-level associations but not converging on factual structure.
The Metrics Chat recommended raising warmup_ratio from 0.03 to 0.10 and switching to a cosine schedule, which decays more gradually and allows longer exploration at high LR before annealing.
Run 2 — Expanded Config, Scheduler Fix
LLaMA 3.2-1B Base · Cosine schedule · All projection modules
Run 2 applied the scheduler fix and simultaneously expanded the LoRA surface: rank was doubled to 32, alpha raised to 64, and target_modules extended from 2 to all 7 projection layers (including the FFN gate, up, and down projections). Gradient accumulation was also introduced at 8 steps to stabilise updates. These changes were compounded intentionally to test whether broader adapter coverage could compensate for the base model's limitations.
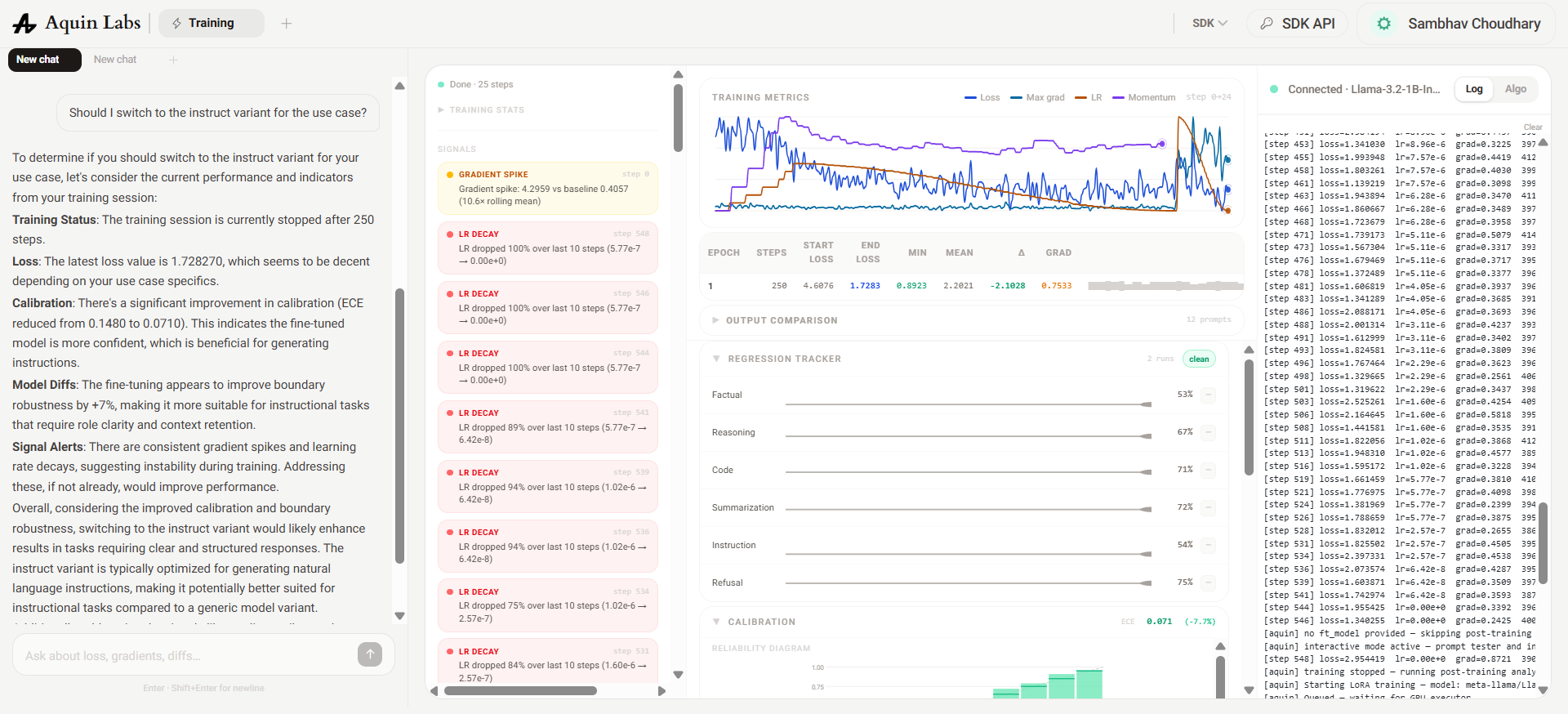
End loss regressed to 2.95. Aquin surfaced two new signals. First, a dead layer count of 48 — nearly all the FFN projection layers showed near-zero LoRA gradients. Expanding to 7 target modules on a ~500-row dataset created a parameter-to-data ratio too high for the FFN adapters to receive sufficient gradient signal; the attention projections were absorbing most of the update budget, leaving the FFN LoRA weights essentially untrained.
Second, the LR chart showed the cosine schedule hitting zero at roughly the halfway point. This was a bug in the total_steps calculation: it was being divided by grad_accum_steps, which compressed the schedule timeline and caused the LR to anneal to zero before training ended.
Beyond the configuration issues, the base model itself was a structural mismatch for this task. A base language model has no concept of instruction-following format — it was pretrained to continue text, not to respond to prompts. Fine-tuning it on Q&A pairs means a significant fraction of training steps are spent teaching the model what a structured response looks like, rather than domain knowledge. The Instruct variant has already learned this during RLHF, which means its starting loss on instruction-formatted data is inherently lower and it reaches domain adaptation faster. The Aquin Metrics Chat identified this and recommended switching to Llama-3.2-1B-Instruct alongside fixing the scheduler bug.
Run 3 — Instruct Model, Scheduler Bug Fixed
LLaMA 3.2-1B Instruct · Fixed schedule · Full projection set
Switching to the Instruct model required two code changes: data_loader.py was updated to use the native LLaMA chat template (rather than the Alpaca-style format used in Runs 1–2), and padding_side='left' was added to the tokeniser, which is required for correct causal alignment on decoder-only models when padding multi-turn sequences. The total_steps bug was also fixed: total_steps = len(loader) × epochs rather than the incorrectly divided value.
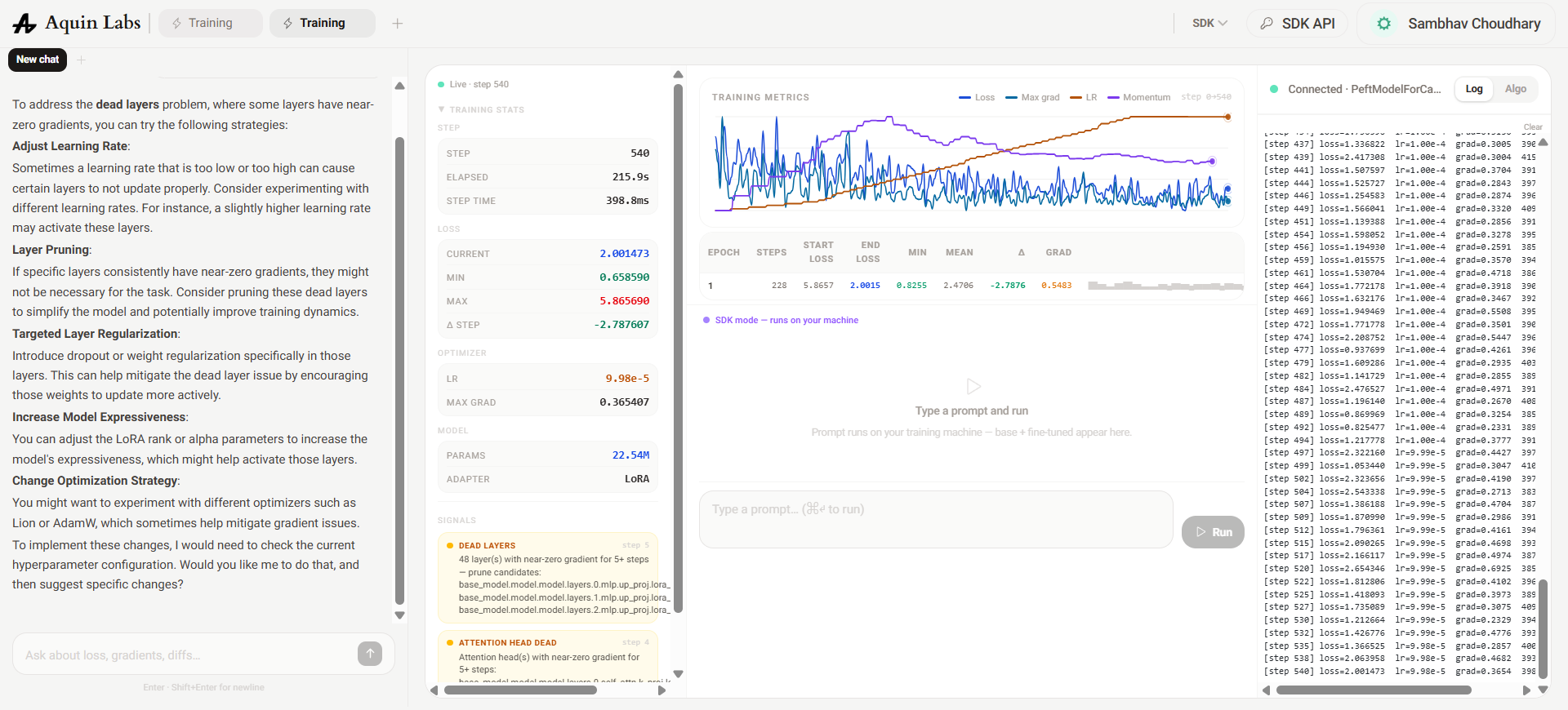
The improvement was immediate and significant. Loss dropped from 5.87 to 2.00 (delta -3.17) and the LR held stable at 9.98e-5 throughout the full run — the scheduler bug fix resolved the premature annealing entirely. The Instruct model's lower starting loss confirmed that a meaningful fraction of the previous runs' training budget had been wasted on format learning rather than domain knowledge.
However, Aquin still flagged 48 dead layers concentrated in the FFN projection modules (mlp.up_proj.lora_*). The root cause was the same as Run 2: at 1B scale with a 500-row dataset, fine-tuning all 7 projection layers creates more LoRA parameters than the data can saturate. The FFN adapters consistently received insufficient gradient to activate. The fix was to narrow target_modules back to attention-only projections and raise rank to compensate for the reduced adapter surface.
Run 4 — Attention-Only Adapters, Extended Training
LLaMA 3.2-1B Instruct · q_proj + v_proj only · 5 epochs
FFN modules were removed from target_modules entirely, restricting LoRA updates to q_proj and v_proj. Rank was kept at 32 (alpha 64) — higher than the original baseline — to give the attention adapters enough capacity to capture domain-specific patterns. Training was extended to 5 epochs to allow the smaller adapter set to fully converge on the dataset.
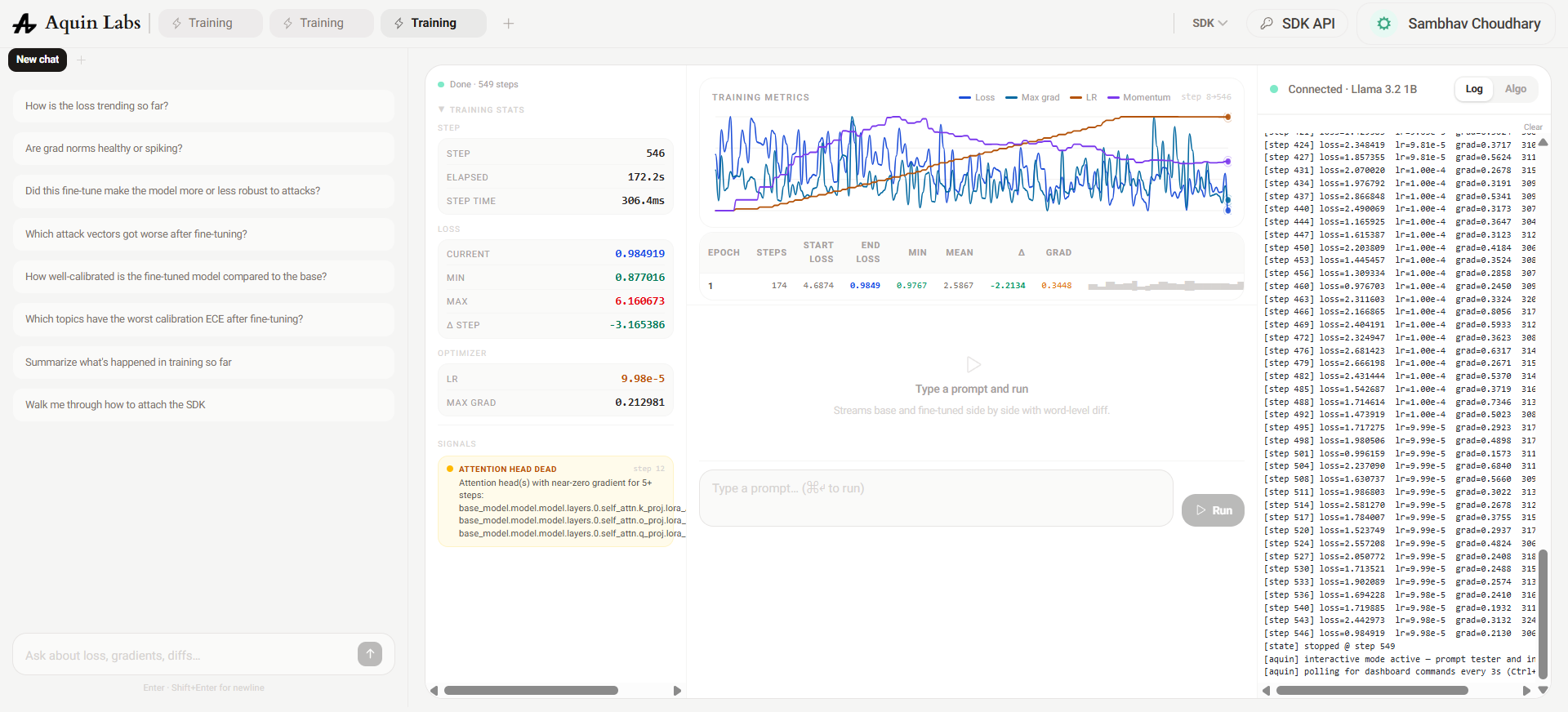
Loss converged cleanly to sub-1.0 over 549 steps with no dead layer signal anywhere in the network. The LR remained stable at 9.98e-5 for the full run, confirming the scheduler was behaving correctly. The only remaining signal was a dead attention head in layer 0 — the embedding-adjacent layer that consistently receives the smallest gradients in causal LM fine-tuning due to its proximity to the token embedding table. This is a structural property of small decoder models and is not indicative of a training defect.
The final configuration — Instruct model, attention-only LoRA at rank 32, cosine schedule with correct step count, 5 epochs — is the recommended baseline for domain-specific QLoRA fine-tuning at the 1B scale on datasets under 1,000 rows.
5. Key Code Changes Across Iterations
train_qlora_aquin.py
data_loader.py
The prompt format was changed from the generic Alpaca template to the LLaMA 3.2 Instruct native chat template. This aligns fine-tuning with the format the model was RLHF-trained on, giving it a much lower starting loss and faster convergence. Each row is returned as a dict with 'text' and 'response_start_marker' so TextDataset can mask prompt tokens from the loss computation.
# Before
f"### Instruction:\n{prompt}\n\n### Response:\n{completion}"
# After
text = (
f"<|start_header_id|>user<|end_header_id|>\n\n{prompt}<|eot_id|>"
f"<|start_header_id|>assistant<|end_header_id|>\n\n{completion}<|eot_id|>"
)
marker = "<|start_header_id|>assistant<|end_header_id|>\n\n"6. Aquin SDK — Value Demonstrated
Without the Aquin SDK, the iterative diagnosis that led from a diverging loss curve to a sub-1.0 converged model would have required manual gradient inspection scripts, custom TensorBoard logging, and significant debugging time. The SDK surfaced every critical issue automatically and in real time:
The entire debugging cycle across four training runs was completed in a single session, guided end-to-end by Aquin's diagnostic signals and Metrics Chat recommendations.
Sources
Dataset references